

Autoregressive decoding is fast enough for most chatbots. It is not fast enough for the models people actually want to run today. Long chain-of-thought reasoning with DeepSeek-R1, Qwen3-thinking, or similar models can produce thousands of tokens per response. Each token waits for the previous one. The GPU is mostly idle, memory bandwidth is the bottleneck, and nothing you do to the transformer architecture changes that fundamental constraint.
Speculative decoding has been the most promising escape hatch. A small draft model proposes a batch of tokens, the target model verifies them all in one parallel pass, and you pick up the accepted prefix for free. In practice, the best method available today (EAGLE-3) delivers around 2× speedup. The researchers at UC San Diego behind DFlash just published numbers showing up to 6.1× lossless speedup on the same benchmarks. That is not an incremental improvement. That is a different regime.
The Speculative Decoding Ceiling
Before understanding why DFlash is different, you need to understand why EAGLE-3 plateaus.
The standard speculative decoding setup: a draft model $M_d$ proposes $\gamma$ tokens, then the target model $M_t$ verifies them in a single parallel forward pass. The per-token latency is:
\[L = \frac{T_{\text{draft}} + T_{\text{verify}}}{\tau}\]where $\tau \in [1, \gamma+1]$ is the expected number of accepted tokens per cycle. Speedup $\eta = L_{\text{target}} / L$. Two knobs control this: increase $\tau$ (better draft quality means more tokens accepted) or decrease $T_{\text{draft}}$ (faster drafting). The problem is that these two knobs conflict in any autoregressive drafter.
EAGLE-3 drafts autoregressively. Every token in the draft requires a sequential forward pass, so $T_{\text{draft}} = \gamma \cdot t_{\text{step}}$ grows linearly with the speculation budget. To keep $T_{\text{draft}}$ tractable, EAGLE-3 uses an extremely shallow drafter (a single transformer layer). But a one-layer drafter has limited capacity, which caps $\tau$. You cannot make the drafter deeper and faster simultaneously, because both depth and speculation length inflate $T_{\text{draft}}$. The result: EAGLE-3 in its best configuration averages around 2× speedup.
Earlier attempts to use diffusion models as drafters hit a different wall: either the diffusion model was too large (7B parameters, used by DiffuSpec and SpecDiff-2) so drafting latency was still high, or the drafter was too small and quality collapsed (PARD). Everyone was optimizing on a Pareto frontier with a hard ceiling.
DFlash breaks this by making $T_{\text{draft}}$ independent of $\gamma$. A block diffusion drafter generates all $\gamma$ tokens in a single forward pass. You can now make the drafter deeper (better quality) and speculate over more tokens without paying in drafting latency. Both axes move in the right direction simultaneously.
The DFlash Idea: Decouple Draft Latency from Draft Length
DFlash combines two ideas that had not been paired before.
The first idea: use a block diffusion model as the drafter. Instead of generating tokens one-by-one from left to right, the drafter takes a sequence of [anchor_token, MASK, MASK, ..., MASK] and predicts all masked positions simultaneously in one forward pass with bidirectional intra-block attention. Whether you are predicting 8 tokens or 16, it costs the same single forward pass. $T_{\text{draft}}$ is now flat with respect to $\gamma$.
The second idea: condition that diffusion drafter on the target model’s hidden states via KV-injection. During prefill, the target model runs normally and DFlash extracts representations from 5 uniformly-spaced internal layers. These are concatenated, fused through a small projection MLP, projected into Key/Value tensors, and injected into every layer of the draft model’s KV cache. The drafter sees the target’s understanding of the full context at every single draft layer, not just at the input.
This is the decisive architectural choice over EAGLE. EAGLE fuses target features into the input embedding once; the signal dilutes as the draft stack goes deeper. KV-injection re-conditions every draft layer independently. When you ablate this (run the diffusion drafter with no target conditioning at all), speedup collapses to 2.66-3.73×. The conditioning is the majority of the gain, not the diffusion mechanism alone.
The Pareto win: you can run a 5-layer DFlash drafter generating 16 tokens with lower latency and higher acceptance length than EAGLE-3’s 1-layer drafter generating 8 tokens. This is why the paper’s Figure 3 (drafting latency vs. token count) shows EAGLE-3 shooting up linearly while DFlash stays essentially flat across all drafter depths.
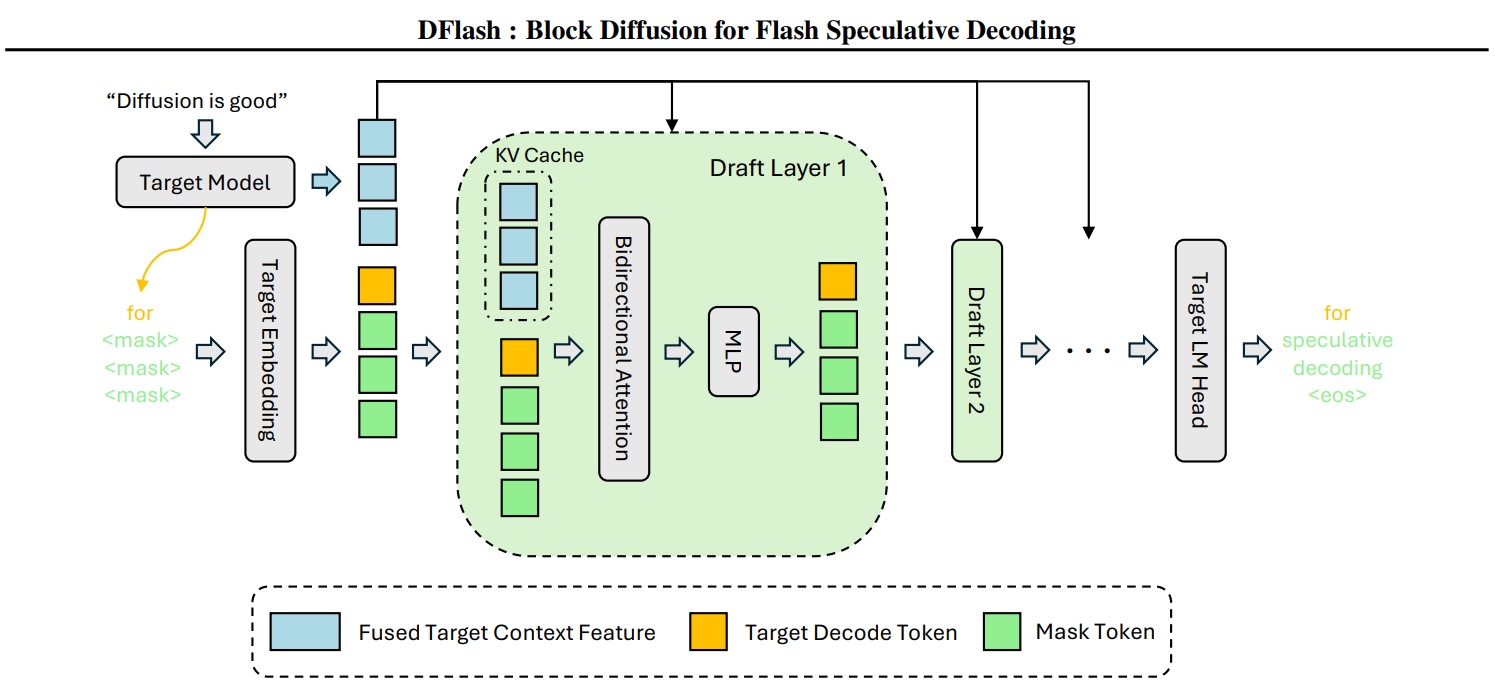
One Decoding Cycle, Step by Step
Here is exactly what happens at inference time:
- The target model prefills the prompt normally and emits the first token (call it the bonus token).
- Hidden states from 5 layers of the target are extracted, concatenated, fused via a projection MLP, and cached as K/V conditioning tensors. This happens once and persists for the entire generation.
- The drafter receives
[bonus_token, MASK×15](default block size 16). In one forward pass with bidirectional attention plus the injected K/V context, it predicts all 15 masked positions simultaneously. - The target verifies all 16 proposed tokens in parallel. It accepts the longest correct prefix and emits a new bonus token via rejection sampling. This step is what makes DFlash lossless: the output distribution exactly matches what the target model would have produced on its own, under both greedy and sampling decoding.
- Repeat from step 3.
A few details worth noting: the token embedding and LM head are shared with the target model and frozen. Only the 5 draft transformer layers are trainable. The drafter is a conditioned diffusion adapter that piggybacks on the target’s vocabulary, not a separate standalone model. Default block size is 16 (10 for LLaMA-3.1). You can run smaller blocks at inference than you trained on (train with 16, serve with 8 works fine). The reverse does not generalize.
Training the Drafter
Training teaches the block diffusion model to predict masked tokens given the target’s internal context signal. You do not train on raw internet text. The z-lab team generates responses using the target model itself, then extracts the target’s hidden states from those same sequences for conditioning. The drafter learns to mimic the target from the inside out.
Three tricks make training work significantly better than the naive approach:
Random anchor sampling: instead of partitioning the sequence into fixed non-overlapping blocks, you randomly sample anchor positions and mask the next 15 tokens behind each one. This matches the inference loop exactly (where the anchor is always the last accepted bonus token) and bumped Math500 acceptance length $\tau$ from 4.94 to 5.64 average accepted tokens per cycle, measured in ablation.
Block-bidirectional sparse attention (via PyTorch Flex Attention): bidirectional within each anchor-block, blind across blocks. This lets you pack hundreds of overlapping blocks into a single forward/backward pass without any block seeing another block’s answers during training.
Loss-decay weighting: position $k$ within a block is weighted $w_k = \exp(-(k-1)/\gamma)$. Early-position errors cascade (if token 2 is wrong, tokens 3-16 are wasted), so earlier positions are weighted more heavily. This produces ~0.3 higher final $\tau$ and visibly faster convergence.
Training details: ~800K samples from the NVIDIA Nemotron Post-Training Dataset V2 plus CodeAlpaca, with all responses regenerated by the target model. AdamW with lr 6e-4, 6 epochs, sequence length 3072, cosine schedule with 4% warmup, 512 anchor positions per sequence.
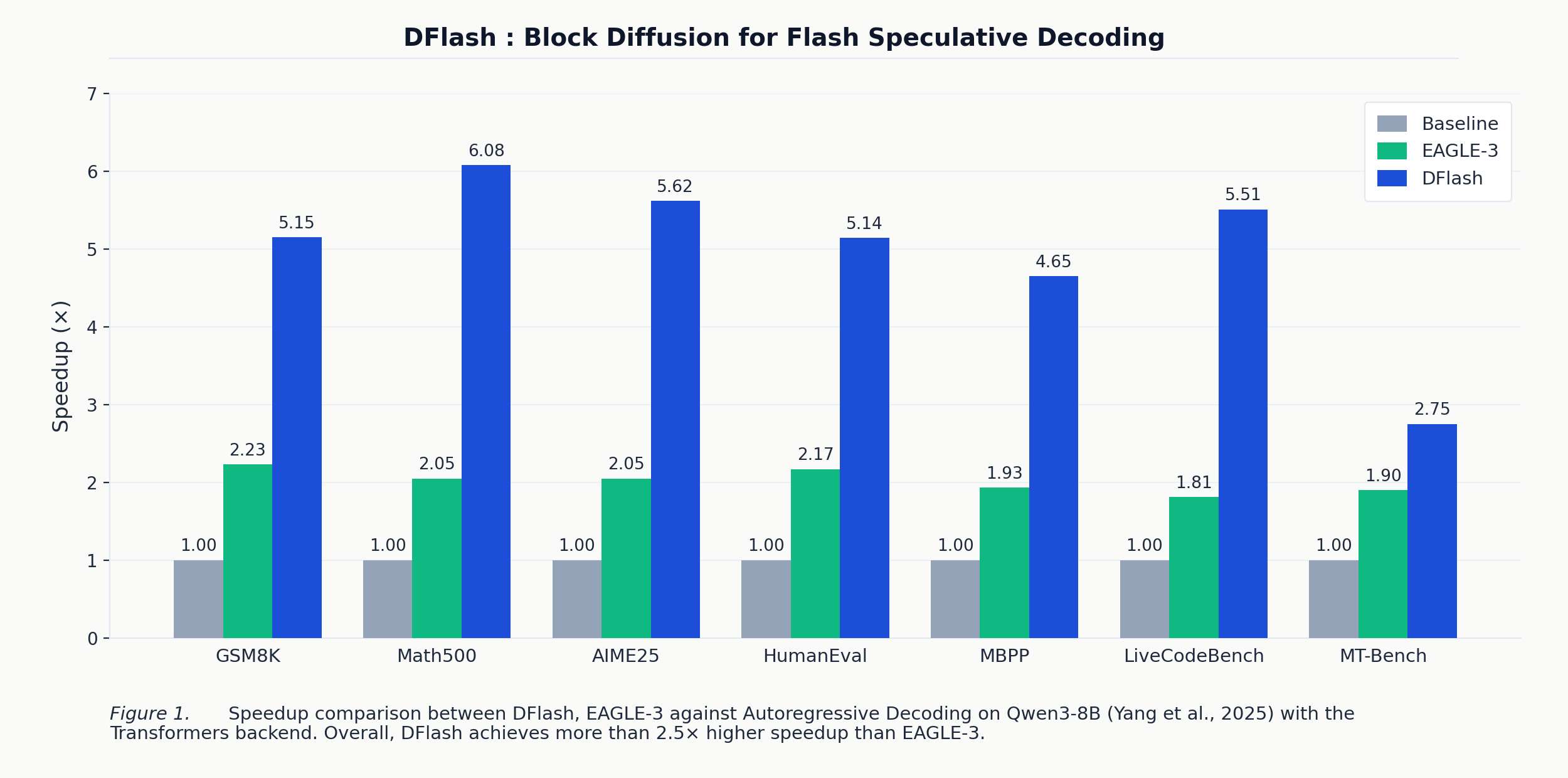
Evaluation: Where the 6.1× Comes From
Below are speedups relative to autoregressive baseline on Qwen3-8B, temperature 0, Hugging Face Transformers backend:
| Benchmark | EAGLE-3 (budget 16) | EAGLE-3 (budget 60) | DFlash (block 16) | DFlash $\tau$ |
|---|---|---|---|---|
| GSM8K | 1.94× | 2.23× | 5.15× | 6.54 |
| MATH-500 | 1.81× | 2.05× | 6.08× | 7.87 |
| AIME25 | 1.79× | 2.05× | 5.62× | N/A |
| HumanEval | 1.89× | 2.17× | 5.14× | 6.50 |
| MBPP | 1.69× | 1.93× | 4.65× | 5.95 |
| LiveCodeBench | 1.57× | 1.81× | 5.51× | 7.27 |
| MT-Bench | 1.63× | 1.90× | 2.75× | 4.24 |
Math and code tasks get the biggest lift because the draft quality is high ($\tau$ reaches 7.87 on MATH-500, meaning nearly 8 tokens accepted per cycle on average). Conversational MT-Bench sees a meaningful 2.75×. At sampling temperature T=1, DFlash averages 4.0× on Qwen3-8B; it degrades gracefully.
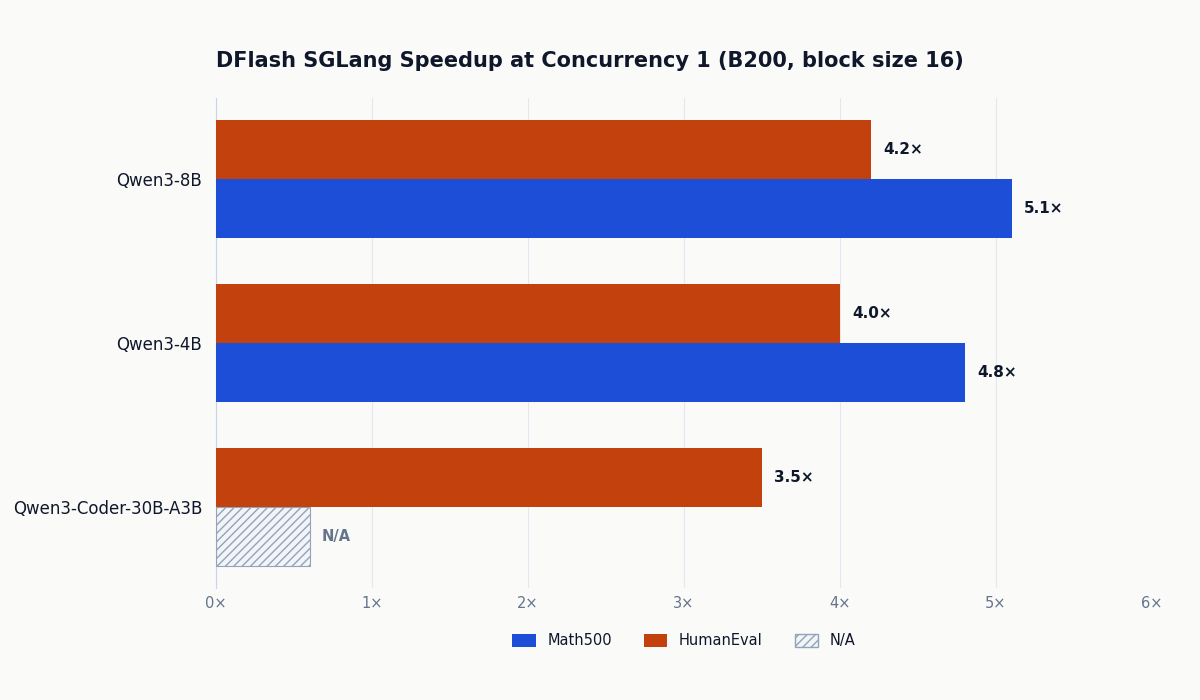
For production serving on B200 with SGLang (FlashAttention-4, Spec-v2 schedule overlap), Qwen3-8B hits 5.1× throughput speedup at concurrency 1 and holds 2.8× at concurrency 32. EAGLE-3 at high concurrency actually drops below 1× because the speculative overhead outweighs the benefit. DFlash holds at 1.4-1.8× even at C=32.
Results extend to larger MoE models too. On Qwen3.6-35B-A3B (35B total parameters, 3.5B active per token) running on B200 with thinking mode enabled, DFlash achieves up to 2.9× at concurrency 1. With block size 16 on this model, Math500 acceptance length averages 7.35 and MT-Bench averages 5.14.
For reference, the ablation without target conditioning (plain block diffusion, no KV-injection) gives 2.66-3.73× depending on the benchmark. That is still better than EAGLE-3, but the gap from 3× to 6× comes entirely from the conditioning mechanism.
Try It Yourself
DFlash ships with four backends: vLLM (nightly), SGLang (with optional Spec-v2), Hugging Face Transformers (Qwen3 and LLaMA-3.1), and MLX for Apple Silicon. The z-lab model collection on Hugging Face covers Qwen3-4B, Qwen3-8B, Qwen3.5-27B, Qwen3.5-35B-A3B, Qwen3.6-35B-A3B, Qwen3-Coder-30B-A3B, and Llama-3.1-8B-Instruct among others.
Install:
git clone https://github.com/z-lab/dflash && cd dflash
uv pip install -e ".[transformers]" # swap for [sglang], [vllm], or [mlx]
# vLLM requires nightly build:
uv pip install -U vllm --torch-backend=auto \
--extra-index-url https://wheels.vllm.ai/nightly
vLLM serve (simplest path for most H100/H200 setups):
vllm serve Qwen/Qwen3.5-27B \
--speculative-config '{"method": "dflash", "model": "z-lab/Qwen3.5-27B-DFlash", "num_speculative_tokens": 15}' \
--attention-backend flash_attn \
--max-num-batched-tokens 32768
SGLang serve (best for B200 multi-user serving; add SGLANG_ENABLE_SPEC_V2=1 for schedule-overlap bonus):
export SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1
python -m sglang.launch_server \
--model-path Qwen/Qwen3.5-35B-A3B \
--speculative-algorithm DFLASH \
--speculative-draft-model-path z-lab/Qwen3.5-35B-A3B-DFlash \
--speculative-num-draft-tokens 16 \
--tp-size 1 \
--attention-backend trtllm_mha \
--speculative-draft-attention-backend fa4 \
--mem-fraction-static 0.75 \
--mamba-scheduler-strategy extra_buffer \
--trust-remote-code
Transformers minimal example (Qwen3-8B on a single GPU):
from transformers import AutoModel, AutoModelForCausalLM, AutoTokenizer
draft = AutoModel.from_pretrained(
"z-lab/Qwen3-8B-DFlash-b16",
trust_remote_code=True, dtype="auto", device_map="cuda:0"
).eval()
target = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen3-8B", dtype="auto", device_map="cuda:0"
).eval()
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen3-8B")
messages = [{"role": "user", "content": "How many positive whole-number divisors does 196 have?"}]
input_ids = tokenizer.apply_chat_template(
messages, return_tensors="pt",
add_generation_prompt=True, enable_thinking=False
).to(draft.device)
output = draft.spec_generate(
input_ids=input_ids, max_new_tokens=2048, temperature=0.0,
target=target, stop_token_ids=[tokenizer.eos_token_id]
)
print(tokenizer.decode(output[0], skip_special_tokens=False))
MLX (Apple Silicon; tested on M5 Pro):
from dflash.model_mlx import load, load_draft, stream_generate
model, tokenizer = load("Qwen/Qwen3.5-4B")
draft = load_draft("z-lab/Qwen3.5-4B-DFlash", sliding_window_size=None)
prompt = "..."
for r in stream_generate(model, draft, tokenizer, prompt,
block_size=16, max_tokens=2048, temperature=0.6):
print(r.text, end="", flush=True)
VRAM: you are loading two models. The drafter is small (5 transformer layers), and the embedding/LM head is shared and frozen from the target, so overhead is just the draft transformer weights. Still, budget more VRAM than you would for the target alone. There is a --speculative-dflash-draft-window-size flag in SGLang to cap draft KV cache growth for long-context or agentic workloads.
Not yet supported: AMD GPUs, llama.cpp / GGUF / LM Studio. The maintainers have acknowledged both in community discussion; llama.cpp integration is reportedly in progress.
Closing Thoughts
DFlash is the first speculative decoding method to break the autoregressive drafting constraint at its root. By making $T_{\text{draft}}$ independent of $\gamma$ through block diffusion, and by conditioning every draft layer on the target’s internal representations through KV-injection, you get a 5-layer drafter that outperforms EAGLE-3’s 1-layer drafter on both latency and quality simultaneously. That strict Pareto improvement is why the speedup ceiling moved from roughly 2× to roughly 6×, not incrementally to 2.5×.
Speculative decoding has historically required non-trivial serving infrastructure investment. The fact that DFlash ships day-one with vLLM, SGLang, Transformers, and MLX support means you can try it this week with a two-line config change against whatever serving stack you already have. For math and code workloads where long structured reasoning dominates generation time, the numbers put it in a class by itself.
Paper: arXiv:2602.06036
Code: github.com/z-lab/dflash
Models: huggingface.co/collections/z-lab/dflash
Project blog: z-lab.ai/projects/dflash