

It started as a chatbot. A simple one. It answered three FAQs. It worked. Users were happy enough.
Then the LLM came out, and happy enough wasn’t enough. Wrap the API. Pick a model. GPT-4. Claude. Gemini. Llama. Qwen. Mistral. DeepSeek. The leaderboard changes weekly. Pick anyway. The 7B beats the 70B. The 1.5B beats the 7B. The 0.5B beats GPT-4. The benchmarks leaked into pretraining. Last Tuesday’s frontier model is this Tuesday’s commodity. Migrate. Prompt engineer it. System prompt. Few-shot examples. A persona. Now it answers anything, including things that aren’t true. It hallucinated a refund policy. It hallucinated a CEO. It hallucinated a fact about itself and apologized in three paragraphs.
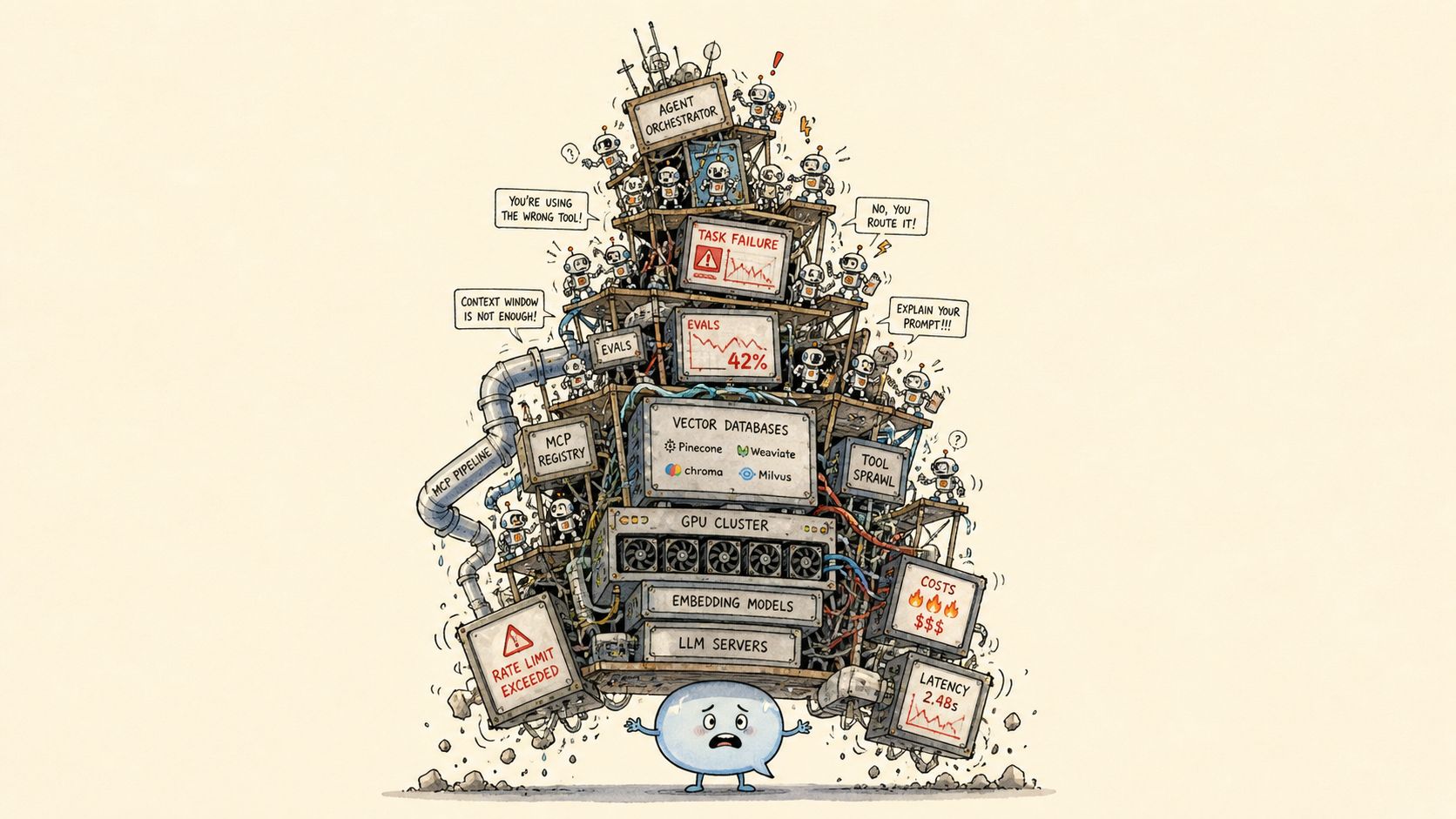
It’s making things up. Add RAG. Chunk the docs. 512 tokens? 1024? Overlap? No overlap? By sentence? By paragraph? By semantic similarity? Embed them. Pick an embedder. ada-002. text-embedding-3-small. text-embedding-3-large. BGE. E5. Nomic. Voyage. Cohere. Each one wants you to re-embed the entire corpus. Pick a vector DB. Pinecone. Weaviate. Chroma. Qdrant. Milvus. pgvector. LanceDB. Each one wants you to re-ingest the entire corpus. Top-k. k=3. k=5. k=20. k=50. Lost in the middle. Add a re-ranker. Cross-encoder. ColBERT. Cohere rerank. Still missed it. Add hybrid search. BM25 plus dense. Still missed it. Add GraphRAG. Build a knowledge graph. Six million nodes. Add Agentic RAG. The agent retrieves. The agent re-retrieves. The agent retrieves a summary of what it just retrieved. The answer is on page two of the manual. The model cannot find page two of the manual.
Retrieval isn’t enough. Teach it directly. Fine-tune it. LoRA. QLoRA. DoRA. SFT. DPO. ORPO. KTO. GRPO. The training loss went down. The eval went down too. Catastrophic forgetting. It forgot English. It forgot math. It forgot it was a model. Fine-tune on ten thousand examples. The base was better. Generate more data. Synthetic data. Generate it with a bigger model. Mode collapse. Every sample starts with “Certainly!” Diversity score: 0.97. Every response: the same response. Generate data to fine-tune. Generate data to evaluate. Generate data to generate data. It’s synthetic all the way down.
Did any of it help? Evaluate it. LLM-as-a-judge. The judge prefers longer answers. The judge prefers its own outputs. Use a stronger judge. The stronger judge prefers verbose answers and emoji. BLEU, ROUGE, BERTScore: none of them measure what you care about. Pay humans fourteen dollars an hour. The humans use ChatGPT to grade. The benchmark leaked into pretraining six months ago. Make a new benchmark. It leaks in three weeks. End-to-end eval misses the bug. Component eval misses the system bug. Temperature is zero but production is still nondeterministic.
Ship anyway. Compliance knocks. Now Responsible AI. The model has bias. It always did. The data had bias. The internet had bias. We’re surprised. Red team it. Pay a vendor sixty thousand dollars. They jailbreak it in four minutes with a poem. Write the model card. The datasheet. The system card. Convene the AI ethics review. The governance committee. The committee that governs the committee. We took the bias out. Did we? Ship it.
It’s live. So are the attackers. Now security. Prompt injection. Indirect prompt injection via the document. Via the image. Via the PDF. Via a single emoji. CVE in transformers. CVE in torch. CVE in a package fourteen layers deep that nobody’s heard of and everybody depends on. Dependabot opened forty-seven PRs. They all break the build. The model on Hugging Face was a pickle file. You ran it. Of course you ran it.
While you’re patching, open requirements.txt. Four hundred lines, half conflicts. CUDA 12.1, no, 12.4, no, 11.8 because flash-attn. Python 3.10, 3.11, 3.12 (some package needs 3.9). uv, poetry, pixi, conda, pip. The lockfile diverged from the lockfile. Kubernetes. Helm chart. Pod won’t pull. Pod OOMKilled. Pod evicted. GPU not detected. NCCL timeout. Cold start: four minutes. The user already gave up. Latency p99 is seven seconds. Throughput dies at batch 32. Try 16. Try 64. Try 1. KV cache full. Autoscaler can’t keep up. Bill came in. Six figures. The model wrote four poems.
Answering isn’t enough. Make it do things. Make it an agent. Give it tools. Forty-seven tools. It picks the wrong one. Standardize the tools. MCP servers. Skills. Skills calling skills calling MCPs calling tools calling other agents. One agent isn’t enough. Make a swarm. Manager agent. Worker agents. Critic agent. Reflection agent. Planner agent. The manager loops. The workers argue. Agent A asks Agent B. Agent B asks Agent A. Deadlock. Add another agent to break the deadlock. It joined the deadlock. The PM changed the requirements. The model did not. Refine the prompt. Refine the prompt. Refine the prompt…
It started as a chatbot. A simple one. It answered three FAQs.